|
|
EDITION #13 SEPTEMBER 2025
|
|
|
Hey there,
This month brought sharper AI tools, rising questions around cost and compliance, and the first signs of real guardrails taking shape.
Let’s break it down.
|
|
|
September in review: Signals behind the noise
|
OpenAI's "Stargate" Reveal: A $100B Bet on Synthetic Data and Post-Training
|
What happened:
A detailed roadmap for OpenAI's "Stargate" project, backed by over $100B from Microsoft, was leaked. The core revelation points to a strategic shift: companies are committing to massive, multi-year efforts to generate and curate high-quality synthetic data, stepping away from the old reliance on web-scale scraping.
The breakdown:
The industry is realizing that the low-hanging fruit of public data is gone. The next frontier is synthetic data engineered for specific reasoning tasks. This leak validates the entire synthetic data market and suggests the next SOTA models will be born from AI-generated, not human-generated, datasets. The focus is shifting from pre-training compute to post-training refinement at an unprecedented scale.
Why it’s relevant:
Your data strategy must now consider synthetic data for filling gaps and stress-testing models. The race is no longer just about who has the most compute, but who has the most intelligent data generation pipeline.
|
Google's "Project Nile" Redefines MLOps with Agentic CI/CD
|
What happened:
Google Cloud unveiled "Project Nile" in private preview, an agentic MLOps platform where AI agents autonomously manage the model lifecycle. The system can self-diagnose drift, trigger retraining pipelines, run canary deployments, and even roll back models based on live performance metrics.
The breakdown:
This marks a move from task automation to genuine delegation, where systems act with agency. Nile uses a sophisticated "agent-of-agents" architecture to oversee data validation, model training, and deployment safety. Early testers report a 70% reduction in manual MLOps intervention. It’s a direct challenge to the manual, script-heavy nature of incumbent platforms.
Why it’s relevant:
The role of the ML Engineer is evolving from pipeline builder to supervisor of autonomous AI systems. Your MLOps stack needs to be agent-ready, with impeccable observability, or it will become obsolete.
|
The EU's "AI Liability Directive" Gets Teeth: Strict Mandate for Model Provenance
|
What happened:
The European Parliament formally adopted the AI Liability Directive, setting a global precedent. It creates a "presumption of causality," meaning if a plaintiff can show a company's AI system caused harm, the burden of proof shifts to the company to prove it was not at fault.
The breakdown:
To defend themselves, companies must provide a complete, immutable audit trail of their model's lifecycle: training data provenance, versioned code, hyperparameters, and all inference logs. This goes far beyond the SEC's guidance, affecting any company doing business in the EU.
Why it’s relevant:
Model cards and vague documentation are no longer sufficient. Your MLAIP (Machine Learning Audit & Integrity Platform) is now a non-negotiable core component of your infrastructure, as critical as your data warehouse.
|
Apache Arrow 16.0 Released with Native "In-Memory Catalog"
|
What happened:
The Apache Arrow project released version 16.0, headlined by a new "In-Memory Catalog" capability. This allows for the management of table metadata, schemas, and partitions directly within the Arrow format, bypassing the need for external metastores for many in-process data workloads.
The breakdown:
By embedding catalog functionality, Arrow 16.0 enables incredibly fast, distributed data operations without a central Hive Metastore or similar service. This is a massive boon for embedded data products, edge analytics, and lightweight data apps that have been bogged down by metastore latency.
Why it’s relevant:
Consider this for your next embedded analytics or edge AI project. It simplifies the architecture and dramatically reduces latency for metadata-heavy operations, further pushing the boundary of what's possible outside the traditional data center.
|
|
|
The Rise of the "Validation Layer"
|
For years, the data stack was obsessed with movement and transformation: ingest data, model it, and serve it. The AI stack was obsessed with modeling and inference: fine-tune, prompt, and generate. In September, a critical pattern emerged: the convergence of these worlds into a new, essential layer focused solely on validation.
We are moving from "move and model" to "validate, then trust".
The failures of costly AI projects and the tightening grip of regulation have made one thing clear: garbage in isn't just garbage out; it's reputational damage, financial loss, and legal liability. This has given rise to a new class of tools and practices dedicated to pre-emptive data validation. We're seeing:
AI-Native Validation:
Using small, fast models to predict the quality and suitability of a dataset for a specific LLM or predictive task.
Agentic Data Stewards:
AI agents that don't just move data but proactively profile it, flag semantic drift, and suggest enrichment before it hits a critical pipeline.
Compliance-as-Code:
Automated checks that embed regulatory requirements (e.g., "no PII in training data for this model") directly into the data fabric.
The validation layer is becoming the most critical (and intelligent) part of the modern data and AI architecture. It's the gatekeeper that ensures what you build is built on a solid foundation.
|
|
|
At Syntaxia, we've felt this pain. Consultants and data engineers end up wrestling with messy, unprepared data far more than they write or configure software.
That's why we're launching ReadyData.
The Problem it Solves:
You're preparing a dataset for a critical customer or project. You spend hours, sometimes days, in a frustrating loop: upload, try to load, get a cryptic error, debug, repeat. It's expensive, demoralizing, and blocks business value.
Our Solution:
ReadyData is your team’s copilot to validate, debug, and greenlight data for client engagements.
Single-Purpose & Focused: It doesn't do transformation or orchestration. It does one thing brilliantly: tell you if your data is ready, grounded on industry ontologies.
Progressive Disclosure: You get an overall score and the top issues first. Drill down with a conversational agent for more detail: "How’s my data looking for SICI?" ... "Is that a blocker?"
Opinionated & Fast: We map your fields to business domain concepts, run our opinionated checks based on decades of implementation experience, and give you a clear, actionable report card in minutes, not days.
Why This Matters Now:
In the era of agentic AI and strict compliance, "hoping" your data is clean is not a strategy. ReadyData brings the validation layer directly to the point of impact, empowering your teams to ship clean, working datasets faster. You’re not replacing your experts; you’re arming them with a powerful force multiplier.
Try it for yourself.
|
|
|
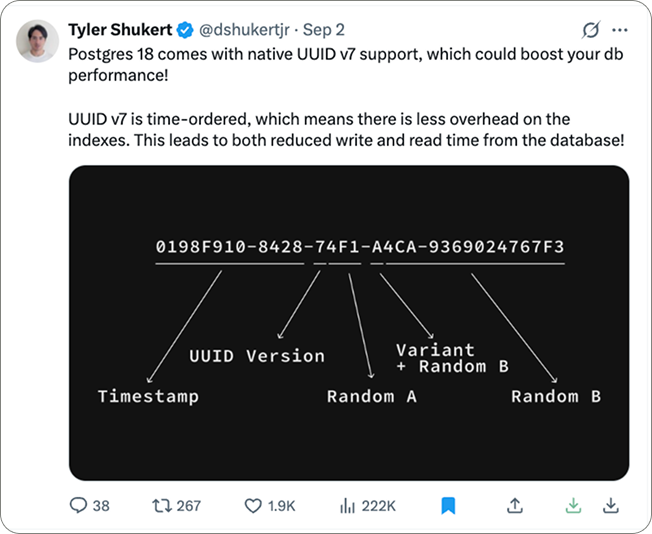
Postgres Upgrade
Version 18 adds native UUID v7 support, making database writes and reads faster.
|
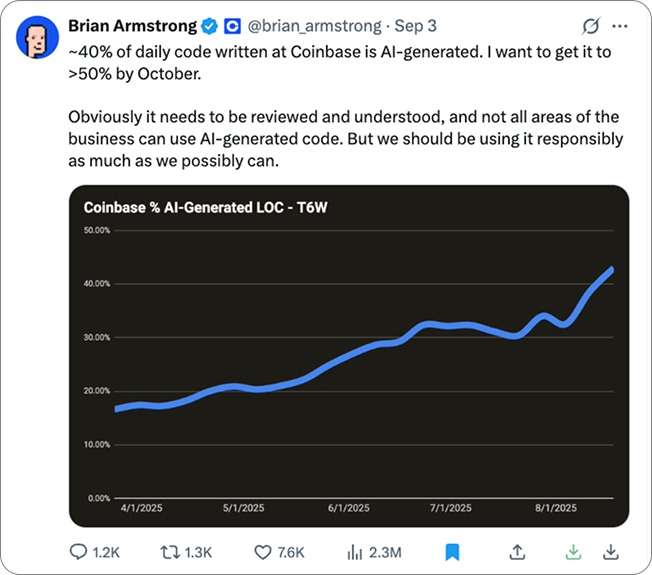
AI at Coinbase
Nearly half of Coinbase’s daily code is now AI-generated, with a push to cross 50%.
|
X Algorithm
X open-sourced more of its recommendation engine, aiming for greater transparency.
|
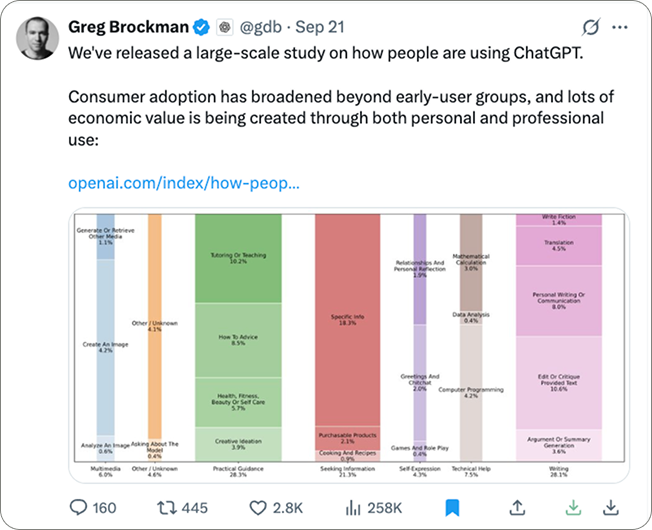
ChatGPT Use Study
OpenAI shared data on how people actually use ChatGPT across work and life.
|
Measuring AI
OpenAI introduced GDPval to track model performance on real-world, economically valuable tasks.
|
Agentic Money
Cloudflare announced a dollar-backed stablecoin (NET Dollar) to fuel instant payments on the agentic web.
|
ChatGPT → Checkout
OpenAI and Stripe roll out the Agentic Commerce Protocol, letting you buy products directly inside ChatGPT.
|
|
|
Tools I found interesting
|
Google's Project Nile SDK
While the full platform is in preview, the SDK offers a glimpse into the agentic MLOps future. Defining a "model health" contract and letting an agent enforce it is a paradigm shift worth experimenting with now.
ReadyData (Syntaxia)
Of course, I'm biased, but our own upcoming product embodies the "Validation Layer" trend. It’s a focused tool that tackles a specific, expensive problem at the intersection of data engineering and business applications.
|
|
|
That’s a wrap for September.
Thanks for reading.
The story doesn’t start here. Explore past editions → The Data Nomad
Quentin
CEO, Syntaxia
quentin.kasseh@syntaxia.com
|
|
|
Copyright © 2025 Syntaxia.
|
|
|
Syntaxia
3480 Peachtree Rd NE, 2nd floor, Suite# 121, Atlanta, Georgia, 30326, United States
|
|
|
|