Hey there,
July was the month of stealth upgrades, infrastructure gambles, and silent shifts in how AI and data systems are built. No flashy keynotes, just real-world adoption, backlash, and reinvention.
Let’s break it down.
|
|
|
July in review: Signals behind the noise
|
OpenAI Quietly Replaces GPT-4o with “GPT-4o Max”
|
What happened:
OpenAI rolled out an unannounced upgrade (GPT-4o Max) with 30% faster token generation, 4K context retention, and a 50% reduction in “lazy model” behavior. Early adopters include Stripe (for dispute resolution) and Notion (for auto-document structuring).
The breakdown:
This upgrade is powered by custom ASICs (not just NVIDIA), enabling lower latency and smoother performance. While the model remains closed-source, competitive pressure, especially from Anthropic’s Claude 3.5, clearly accelerated OpenAI’s hand.
Why it’s relevant:
The “free silent upgrade” era is here. If your app depends on OpenAI’s API, your UX just improved without you lifting a finger.
|
Databricks Launches “Lakehouse AI”, A Direct Shot at Snowflake
|
What happened:
Databricks unveiled Lakehouse AI, bundling MLflow 3.0, Unity Catalog governance, and real-time feature serving into one stack. Snowflake retaliated by open-sourcing their Polaris Query Engine.
The breakdown:
Lakehouse AI combines faster batch/streaming unification (allegedly 2x faster than Snowpark) with native MLflow and real-time feature serving. Snowflake’s response? Open-sourcing the Polaris Query Engine to counter the “Delta Lake lock-in” narrative.
Why it’s relevant:
The data platform war is now an AI war. Choosing a stack now locks you into its ML ecosystem.
|
Kubernetes 1.40 Introduces “AI-Optimized Nodes”
|
What happened:
K8s 1.40 added native support for LLM inference pods, auto-scaling based on token throughput (not just CPU/RAM).
The breakdown:
NVIDIA’s Device Plugin now orchestrates H100s at scale, treating them like disposable infrastructure. Major clouds also greenlit preemptible GPU workloads, making spot inference a viable (and cheaper) deployment option.
Why it’s relevant:
DevOps teams can finally treat AI workloads like web servers, but monitoring “tokens/sec” is the new challenge.
|
EU’s AI Act Compliance Tools Are Failing Audits
|
What happened:
IBM’s AI Governance Toolkit and Salesforce’s Ethics Engine flunked independent audits for bias detection gaps.
The breakdown:
Audit reports reveal 22% false-negative rates in edge cases, particularly around multilingual or non-standard inputs. Despite bold marketing claims, tools from IBM and Salesforce still require significant manual review to be considered trustworthy.
Why it’s relevant:
Regulators are calling BS on “AI governance SaaS.” In-house audits are back in vogue.
|
Rust Overtakes Go in Data Engineering (At Last)
|
What happened:
Apache Arrow 15.0 shipped with Rust-native DataFrame APIs, and Polars 1.0 hit production benchmarks 2x faster than PySpark.
The breakdown:
With Apache Arrow 15.0 and Polars 1.0 hitting impressive benchmarks, companies like Meta and Netflix are shifting pipelines to Rust. Go’s garbage collection delays are proving too slow for real-time workloads, and Rust’s low-level control is winning out.
Why it’s relevant:
If you’re still writing Python UDFs, it’s time to test Rust + WASM.
|
|
|
The Silent Rise of “AI-Native Databases”
|
For years, AI lived on the edges of our databases, plugged in through scripts, APIs, or external tools. But that model is starting to flip. A new wave of “AI-native” databases is emerging, not as bolt-ons, but as purpose-built environments where inference, search, and storage converge.
PostgreSQL is leading the charge. With pgvector now integrated across platforms like ParadeDB, Neon, and Lantern, Postgres can handle both structured SQL and vector search in the same query plan. For many use cases, this eliminates the need for a separate vector database entirely, reducing architectural sprawl and improving latency.
MongoDB is evolving too. Its Atlas Vector Search now supports multi-modal embeddings (text, audio, image) all in one queryable interface. Spotify uses it to build playlist recommendations; TikTok applies it for high-resolution ad targeting. These are no longer experiments. They're production tools.
But there's a hidden cost. To deliver sub-second responses, AI-native databases often pre-warm models in memory. That cuts down cold start time, but it doubles cloud costs. The tradeoff between speed and spend is back on the table.
The shift is subtle, but foundational: inference is moving inside the database layer. For engineers and architects, this not only changes performance tuning but it changes how we design entire systems.
|
|
|
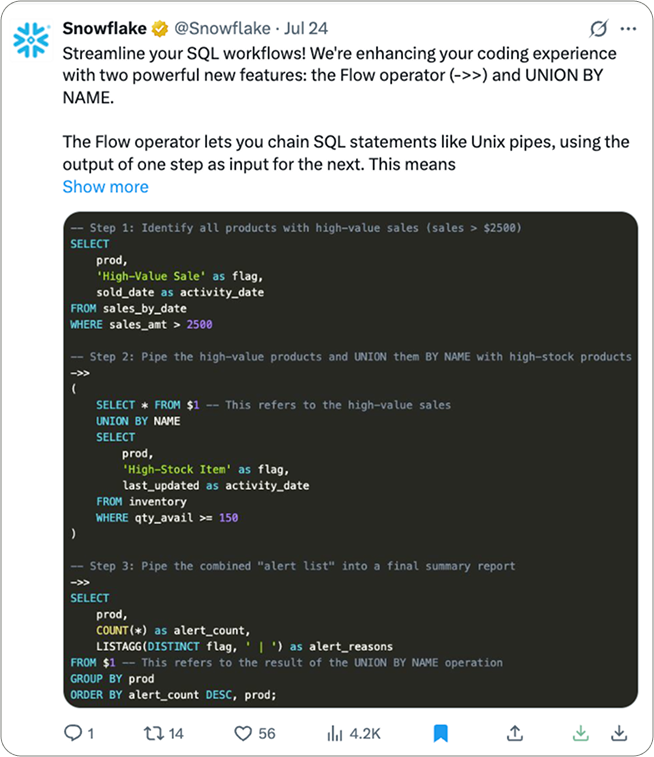
Snowflake SQL Enhancements
SQL just got pipes and smarter UNIONs. Clean.
|
Signull on iCloud Storage
We’re all hoarding memories in the cloud.
|
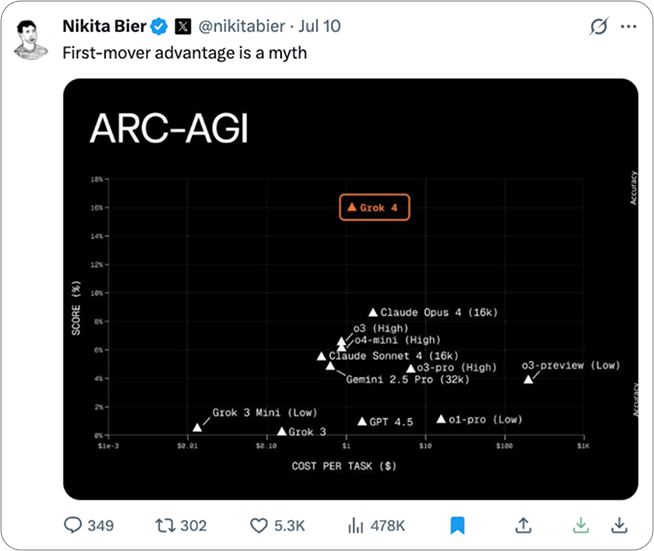
ARC-AGI Chart (Grok 4)
Grok 4 lands way above the pack on ARC-AGI.
|
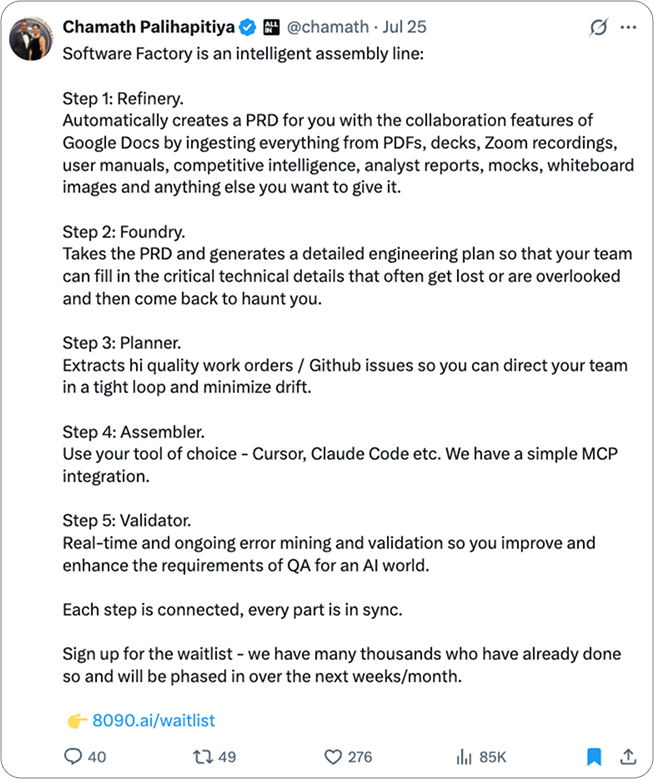
Chamath: Software Factory Launch
AI turning specs into code into issues, assembly line vibes.
|
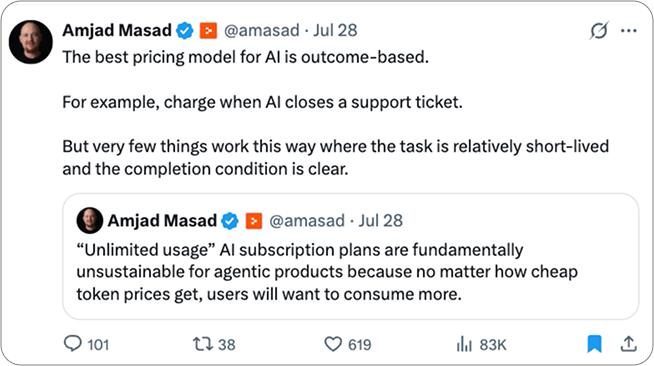
Amjad Masad on AI Pricing
Outcome-based AI pricing sounds great…until you try it.
|
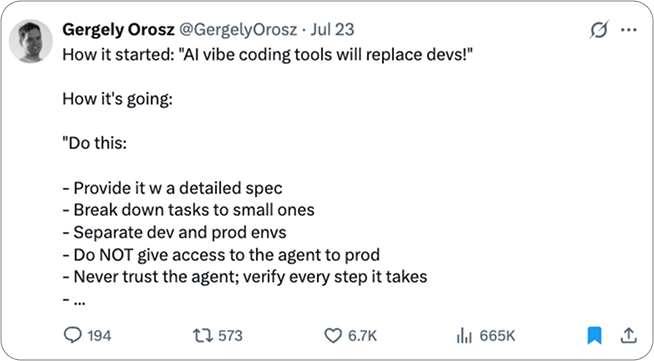
Gergely Orosz on AI Agents
“Replace devs” turned into “micromanage your agent.”
|
|
|
Tools I found interesting
|
A few sharp tools and concepts I'm working with, battle-tested and real-world applicable.
Snowflake Semantic View Generator (Cortex Analyst):
Build semantic models with a GUI, store them as YAML. Drag, drop, deploy. No SQL needed.
Mistral’s Codestral 2.0:
Self-debugging code model that edits its own PRs. Git history is getting attention. So far this is good in young repos.
dbt-labs/ml:
Machine learning inside SQL. Train XGBoost models via dbt run.
|
|
|
That’s a wrap for July. Whether it’s databases, DevOps, or data pipelines, the infrastructure is learning.
Thanks for reading.
The story doesn’t start here. Explore past editions → The Data Nomad
Quentin
CEO, Syntaxia
quentin.kasseh@syntaxia.com
|
|
|
Copyright © 2025 Syntaxia.
|
|
|
Syntaxia
113 S. Perry Street, Suite 206 #11885, Lawrenceville, Georgia, 30046, United States
|
|
|
|